Manipulating Tibbles With Dplyr
Last updated on 2024-12-10 | Edit this page
Estimated time: 55 minutes
Overview
Questions
- How can I manipulate data frames without repeating myself?
Objectives
- To be able to use the six main data frame manipulation ‘verbs’ with
pipes in
dplyr. - To understand how
group_by()andsummarize()can be combined to summarize datasets. - Be able to analyze a subset of data using logical filtering.
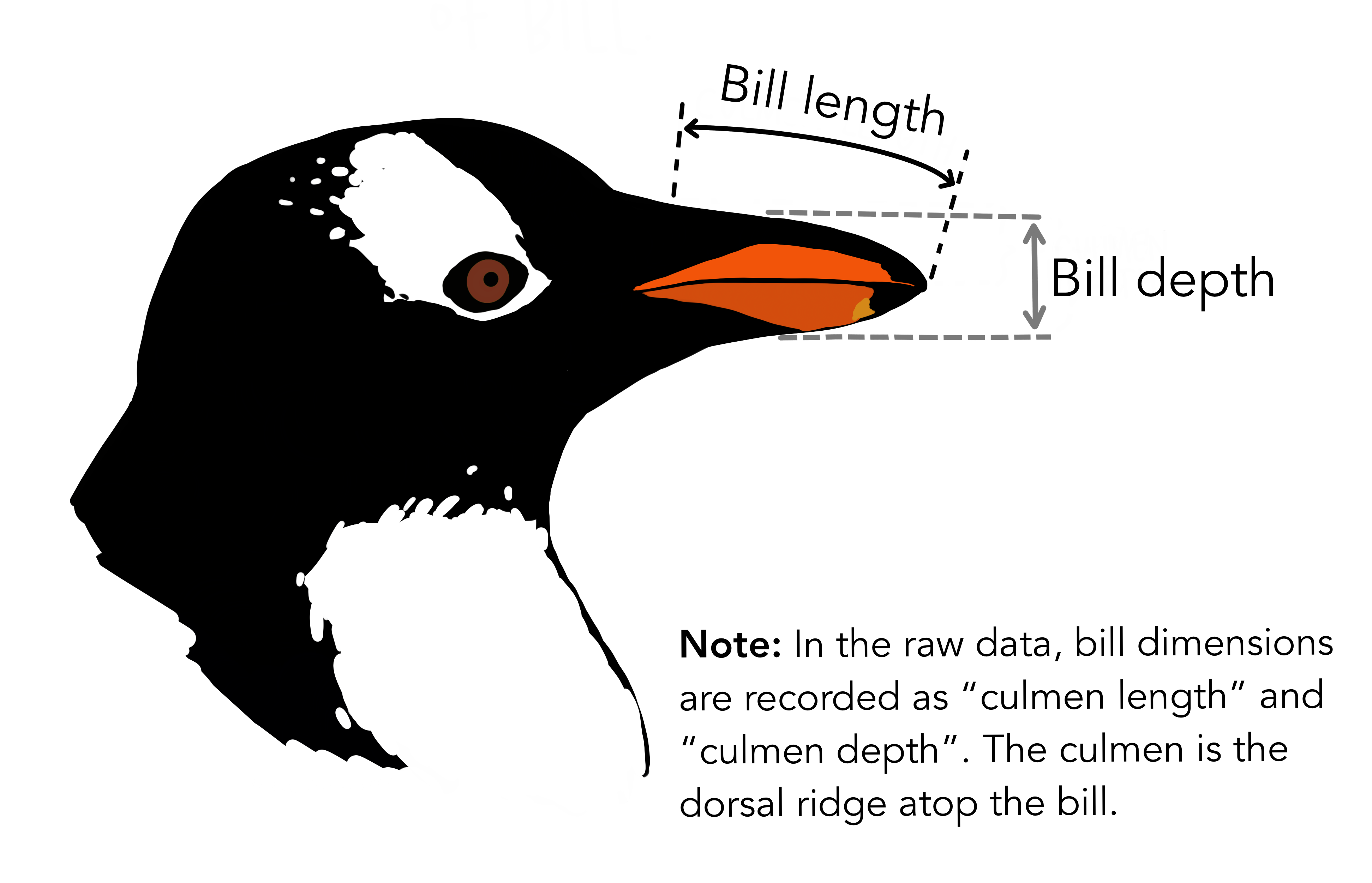
In this episode we’ll start to work with the penguins data directly. This is a version of the Palmer Penguins dataset that has been adapted for teaching. All missing values have been replaced with the sample mean / mode for convenience. The columns bill_length_mm and bill_depth_mm are defined as illustrated below.
Manipulation of data frames means many things to many researchers: we often select certain observations (rows) or variables (columns), we often group the data by a certain variable(s), or we even calculate summary statistics. We can do these operations using the normal base R operations:
OUTPUT
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsR
mean(penguins$body_mass_g[penguins$species == "Adelie"])
OUTPUT
[1] 3703.959R
mean(penguins$body_mass_g[penguins$species == "Chinstrap"])
OUTPUT
[1] 3733.088R
mean(penguins$body_mass_g[penguins$species == "Gentoo"])
OUTPUT
[1] 5068.966But this isn’t very nice because there is a fair bit of repetition. Repeating yourself will cost you time, both now and later, and potentially introduce some nasty bugs.
The dplyr package
Luckily, the dplyr
package provides a number of very useful functions for manipulating data
frames in a way that will reduce the above repetition, reduce the
probability of making errors, and probably even save you some typing. As
an added bonus, you might even find the dplyr grammar
easier to read.
Tip: Tidyverse
dplyr package belongs to a broader family of opinionated
R packages designed for data science called the “Tidyverse”. These
packages are specifically designed to work harmoniously together. Some
of these packages will be covered along this course, but you can find
more complete information here: https://www.tidyverse.org/.
If you have have not installed the tidyverse package earlier, please do so:
R
install.packages('tidyverse')
Now let’s load the package:
R
library("tidyverse")
Here we’re going to cover 5 of the most commonly used
dplyr functions as well as using pipes (|>)
to combine them.
select()filter()group_by()summarize()mutate()
But first we need to highlight some key differences between how base R and the tidyverse handle tabular data.
Let’s make a new script for this episode, by choosing the menu options File, New File, R Script.
One key thing to note is that the tidyverse duplicates many base R
functions e.g.
we can load our dataset using the tidyverse function
read_csv rather than read.csv:
R
library(tidyverse)
penguins <- read_csv("data/penguins_teaching.csv", col_types = cols(year = col_character()))
penguins
OUTPUT
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 43.9 17.2 201. 4202.
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <chr>, year <chr>Notice that we specify that the year column should be loaded as text (character data type). We do this because as the dataset only contains three year’s worth of data we want to treat “year” as a categorical variable. It is helpful when plotting to store this categorical variable as text.
We can see that penguins consists of a 344 by 8 tibble.
We see the variable names, and an abbreviation indicating what type of
data is stored in each variable.
A tibble is a way of storing tabular data - a modern version of data
frames, which is part of the tidyverse. Tibbles can for the most part,
be treated like a data.frame.
Callout
R’s standard data structure for tabular data is the
data.frame. In contrast, read_csv() creates a
tibble (also referred to, for historic reasons, as a
tbl_df). This extends the functionality of a
data.frame, and can, for the most part, be treated like a
data.frame.
You may find that some older functions don’t work on tibbles. A
tibble can be converted to a dataframe using
as.data.frame(mytibble). To convert a data frame to a
tibble, use as.tibble(mydataframe).
Tibbles behave more consistently than data frames when subsetting
with []; this will always return another tibble. This isn’t
the case when working with data.frames. You can find out more about the
differences between data.frames and tibbles by typing
vignette("tibble").
Using select()
If, for example, we wanted to move forward with only a few of the
variables in our data frame we could use the select()
function. This will keep only the variables you select.
R
year_island_bmg <- select(penguins, year, island, body_mass_g)
head(year_island_bmg)
OUTPUT
# A tibble: 6 × 3
year island body_mass_g
<chr> <chr> <dbl>
1 2007 Torgersen 3750
2 2007 Torgersen 3800
3 2007 Torgersen 3250
4 2007 Torgersen 4202.
5 2007 Torgersen 3450
6 2007 Torgersen 3650 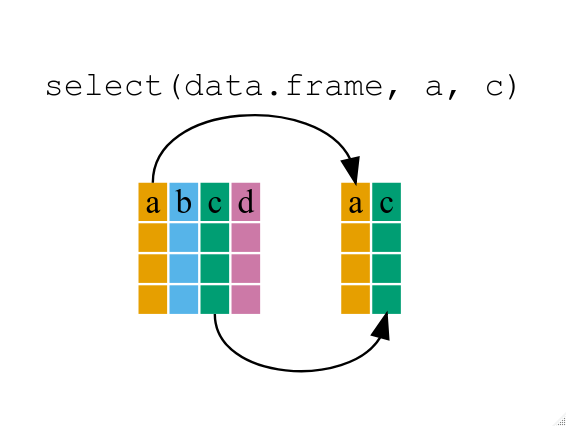
If we open up year_island_bmg we’ll see that it only
contains the year, island and body mass (g).
Note that we can also use select to remove columns we don’t want in our dataset:
R
noyear_noisland_nobmg <- select(penguins, -year, -island, -body_mass_g)
head(noyear_noisland_nobmg)
OUTPUT
# A tibble: 6 × 5
species bill_length_mm bill_depth_mm flipper_length_mm sex
<chr> <dbl> <dbl> <dbl> <chr>
1 Adelie 39.1 18.7 181 male
2 Adelie 39.5 17.4 186 female
3 Adelie 40.3 18 195 female
4 Adelie 43.9 17.2 201. male
5 Adelie 36.7 19.3 193 female
6 Adelie 39.3 20.6 190 male Above we used ‘normal’ grammar, but the strengths of
dplyr lie in combining several functions using pipes. Since
the pipes grammar is unlike anything we’ve seen in R before, let’s
repeat what we’ve done above using pipes.
R
# before: year_island_bmg <- select(penguins, year, island, body_mass_g)
year_island_bmg <- penguins |> select(year, island, body_mass_g)
head(year_island_bmg)
OUTPUT
# A tibble: 6 × 3
year island body_mass_g
<chr> <chr> <dbl>
1 2007 Torgersen 3750
2 2007 Torgersen 3800
3 2007 Torgersen 3250
4 2007 Torgersen 4202.
5 2007 Torgersen 3450
6 2007 Torgersen 3650 To help you understand why we wrote that in that way, let’s walk
through it step by step. First we summon the penguins data frame and
pass it on, using the pipe symbol |>, to the next step,
which is the select() function. In this case we don’t
specify which data object we use in the select() function
since it gets that from the previous pipe. Fun Fact:
There is a good chance you have encountered pipes before in the shell.
In R, a pipe symbol is |> while in the shell it is
| but the concept is the same!
Tip: Renaming data frame columns in dplyr
In Chapter 4 we covered how you can rename columns with base R by
assigning a value to the output of the names() function.
Just like select, this is a bit cumbersome, but thankfully dplyr has a
rename() function.
Within a pipeline, the syntax is
rename(new_name = old_name). For example, we may want to
rename the island column name from our select() statement
above.
R
tidy_bmg <- year_island_bmg |> rename(island_name = island)
head(tidy_bmg)
OUTPUT
# A tibble: 6 × 3
year island_name body_mass_g
<chr> <chr> <dbl>
1 2007 Torgersen 3750
2 2007 Torgersen 3800
3 2007 Torgersen 3250
4 2007 Torgersen 4202.
5 2007 Torgersen 3450
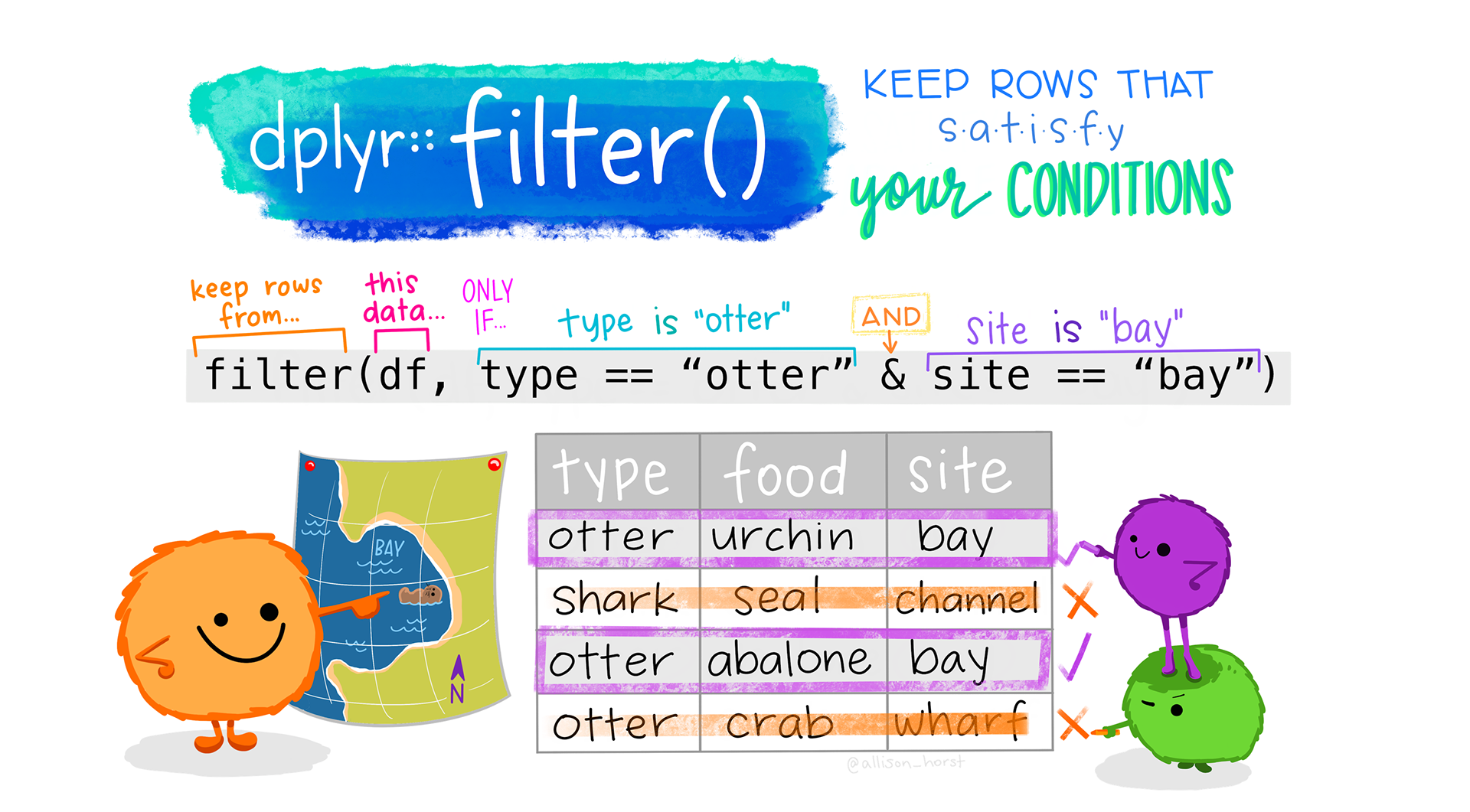
6 2007 Torgersen 3650 Using filter()
If we now want to move forward with the above, but only with
observations for the island of “Dream”, we can combine
select and filter
R
dream_year_island_bmg <- penguins |>
filter(island == "Dream") |>
select(year, body_mass_g)
head(dream_year_island_bmg)
OUTPUT
# A tibble: 6 × 2
year body_mass_g
<chr> <dbl>
1 2007 3250
2 2007 3900
3 2007 3300
4 2007 3900
5 2007 3325
6 2007 4150Notice how this code is indented and formatted over multiple lines to improve readability.
If we now want to show body mass of penguin species on Dream island but only for a specific year (e.g., 2007), we can do as below.
R
dream_island_2007 <- penguins |>
filter(island == "Dream", year == "2007") |>
select(species, body_mass_g)
head(dream_island_2007)
OUTPUT
# A tibble: 6 × 2
species body_mass_g
<chr> <dbl>
1 Adelie 3250
2 Adelie 3900
3 Adelie 3300
4 Adelie 3900
5 Adelie 3325
6 Adelie 4150Notice that 2007 is in quotes (“2007”) as the year column is stored as text (character datatype).
As with last time, first we pass the penguins data frame to the
filter() function, then we pass the filtered version of the
penguins data frame to the select() function.
Note: The order of operations is very important in this
case. If we used ‘select’ first, filter would not be able to find the
variable island since we would have removed it in the
previous step.
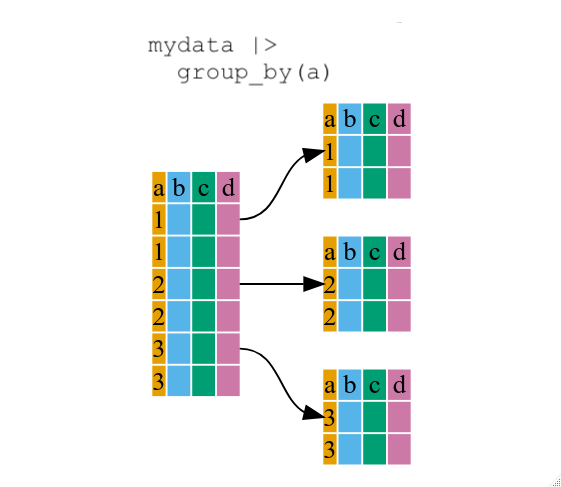
Using group_by()
Now, we were supposed to be reducing the error prone repetitiveness
of what can be done with base R, but up to now we haven’t done that
since we would have to repeat the above for each island Instead of
filter(), which will only pass observations that meet your
criteria (in the above: island=="Dream"), we can use
group_by(), which will essentially use every unique
criteria that you could have used in filter.
R
str(penguins)
OUTPUT
spc_tbl_ [344 × 8] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ species : chr [1:344] "Adelie" "Adelie" "Adelie" "Adelie" ...
$ island : chr [1:344] "Torgersen" "Torgersen" "Torgersen" "Torgersen" ...
$ bill_length_mm : num [1:344] 39.1 39.5 40.3 43.9 36.7 ...
$ bill_depth_mm : num [1:344] 18.7 17.4 18 17.2 19.3 ...
$ flipper_length_mm: num [1:344] 181 186 195 201 193 ...
$ body_mass_g : num [1:344] 3750 3800 3250 4202 3450 ...
$ sex : chr [1:344] "male" "female" "female" "male" ...
$ year : chr [1:344] "2007" "2007" "2007" "2007" ...
- attr(*, "spec")=
.. cols(
.. species = col_character(),
.. island = col_character(),
.. bill_length_mm = col_double(),
.. bill_depth_mm = col_double(),
.. flipper_length_mm = col_double(),
.. body_mass_g = col_double(),
.. sex = col_character(),
.. year = col_character()
.. )
- attr(*, "problems")=<externalptr> R
str(penguins |> group_by(island))
OUTPUT
gropd_df [344 × 8] (S3: grouped_df/tbl_df/tbl/data.frame)
$ species : chr [1:344] "Adelie" "Adelie" "Adelie" "Adelie" ...
$ island : chr [1:344] "Torgersen" "Torgersen" "Torgersen" "Torgersen" ...
$ bill_length_mm : num [1:344] 39.1 39.5 40.3 43.9 36.7 ...
$ bill_depth_mm : num [1:344] 18.7 17.4 18 17.2 19.3 ...
$ flipper_length_mm: num [1:344] 181 186 195 201 193 ...
$ body_mass_g : num [1:344] 3750 3800 3250 4202 3450 ...
$ sex : chr [1:344] "male" "female" "female" "male" ...
$ year : chr [1:344] "2007" "2007" "2007" "2007" ...
- attr(*, "spec")=
.. cols(
.. species = col_character(),
.. island = col_character(),
.. bill_length_mm = col_double(),
.. bill_depth_mm = col_double(),
.. flipper_length_mm = col_double(),
.. body_mass_g = col_double(),
.. sex = col_character(),
.. year = col_character()
.. )
- attr(*, "problems")=<externalptr>
- attr(*, "groups")= tibble [3 × 2] (S3: tbl_df/tbl/data.frame)
..$ island: chr [1:3] "Biscoe" "Dream" "Torgersen"
..$ .rows : list<int> [1:3]
.. ..$ : int [1:168] 21 22 23 24 25 26 27 28 29 30 ...
.. ..$ : int [1:124] 31 32 33 34 35 36 37 38 39 40 ...
.. ..$ : int [1:52] 1 2 3 4 5 6 7 8 9 10 ...
.. ..@ ptype: int(0)
..- attr(*, ".drop")= logi TRUEYou will notice that the structure of the data frame where we used
group_by() (grouped_df) is not the same as the
original penguins (data.frame). A
grouped_df can be thought of as a list where
each item in the listis a data.frame which
contains only the rows that correspond to the a particular value
island (at least in the example above).
Callout
You may have noticed this output when using the group_by() function:
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.`summarise()` has grouped output by 'year'. This indicates that the dataset we are working with was grouped by a variable (in this case, year) using a function like group_by(year) before applying summarise().
The result of summarise() will maintain the grouping structure unless explicitly changed.
You can override using the `.groups` argument.The .groups argument in summarise() lets you control how grouping is handled in the output. By default, summarise() keeps one level of grouping intact (i.e., the result remains grouped by any other grouping variables, if present). You can override this behaviour by specifying .groups explicitly.
The possible values for .groups are: - “drop_last” (default): Drops the last grouping variable (e.g., if grouped by year and month, it drops month but keeps year). - “drop”: Removes all grouping - “keep”: Keeps all grouping variables intact.
Using summarize()
The above was a bit on the uneventful side but
group_by() is much more exciting in conjunction with
summarize(). This will allow us to create new variable(s)
by using functions that repeat for each of the group-specific data
frames. That is to say, using the group_by() function, we
split our original data frame into multiple pieces, then we can run
functions (e.g. mean() or sd()) within
summarize().
R
bm_byspecies <- penguins |>
group_by(species) |>
summarize(mean_body_mass_g = mean(body_mass_g))
head(bm_byspecies)
OUTPUT
# A tibble: 3 × 2
species mean_body_mass_g
<chr> <dbl>
1 Adelie 3704.
2 Chinstrap 3733.
3 Gentoo 5069.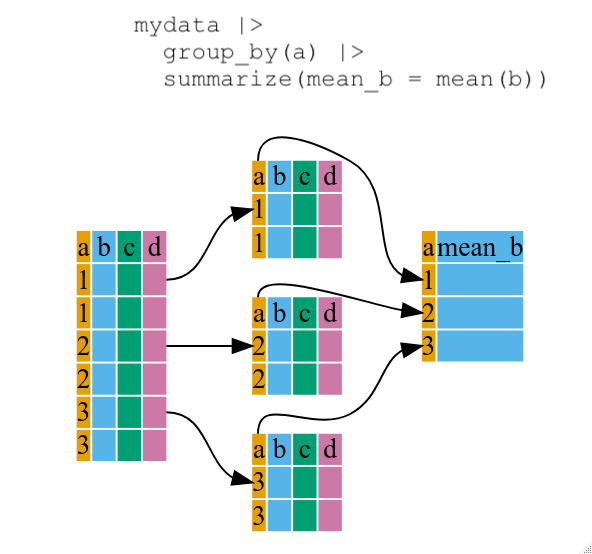
That allowed us to calculate the mean body_mass_g for each species, but it gets even better.
The function group_by() allows us to group by multiple
variables. Let’s group by year and
species.
R
bm_byyear_byspecies <- penguins |>
group_by(year, species) |>
summarize(mean_body_mass_g = mean(body_mass_g))
OUTPUT
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.R
head(bm_byyear_byspecies)
OUTPUT
# A tibble: 6 × 3
# Groups: year [2]
year species mean_body_mass_g
<chr> <chr> <dbl>
1 2007 Adelie 3707.
2 2007 Chinstrap 3694.
3 2007 Gentoo 5071.
4 2008 Adelie 3742
5 2008 Chinstrap 3800
6 2008 Gentoo 5020.That is already quite powerful, but it gets even better! You’re not
limited to defining 1 new variable in summarize().
R
bm_byyear_byspecies <- penguins |>
group_by(year, species) |>
summarize(
mean_body_mass_g = mean(body_mass_g),
sd_body_mass_g = sd(body_mass_g)
)
OUTPUT
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.R
head(bm_byyear_byspecies)
OUTPUT
# A tibble: 6 × 4
# Groups: year [2]
year species mean_body_mass_g sd_body_mass_g
<chr> <chr> <dbl> <dbl>
1 2007 Adelie 3707. 451.
2 2007 Chinstrap 3694. 328.
3 2007 Gentoo 5071. 583.
4 2008 Adelie 3742 455.
5 2008 Chinstrap 3800 519.
6 2008 Gentoo 5020. 515.count() and n()
A very common operation is to count the number of observations for
each group. The dplyr package comes with two related
functions that help with this.
For instance, if we wanted to check the number of penguins included
in the dataset for the year 2007, we can use the count()
function. It takes the name of one or more columns that contain the
groups we are interested in, and we can optionally sort the results in
descending order by adding sort=TRUE:
R
penguins |>
filter(year == "2007") |>
count(island, sort = TRUE)
OUTPUT
# A tibble: 3 × 2
island n
<chr> <int>
1 Dream 46
2 Biscoe 44
3 Torgersen 20If we need to use the number of observations in calculations, the
n() function is useful. It will return the total number of
observations in the current group rather than counting the number of
observations in each group within a specific column. For instance, if we
wanted to get the standard error of the body mass for penguins on each
island:
R
penguins |>
group_by(island) |>
summarize(se_bm = sd(body_mass_g)/sqrt(n()))
OUTPUT
# A tibble: 3 × 2
island se_bm
<chr> <dbl>
1 Biscoe 60.3
2 Dream 37.4
3 Torgersen 61.9You can also chain together several summary operations; in this case
calculating the minimum, maximum,
mean and se of body_mass_g on each island:
R
penguins |>
group_by(island) |>
summarize(
mean_bm = mean(body_mass_g),
min_bm = min(body_mass_g),
max_bm = max(body_mass_g),
se_bm = sd(body_mass_g)/sqrt(n())
)
OUTPUT
# A tibble: 3 × 5
island mean_bm min_bm max_bm se_bm
<chr> <dbl> <dbl> <dbl> <dbl>
1 Biscoe 4713. 2850 6300 60.3
2 Dream 3713. 2700 4800 37.4
3 Torgersen 3716. 2900 4700 61.9Using mutate()
We can also create new variables prior to (or even after) summarizing
information using mutate().
R
bm_byyear_byisland_byspecies <- penguins |>
mutate(body_mass_kg = body_mass_g/1000) |>
group_by(year, island, species) |>
summarize(
mean_body_mass_kg = mean(body_mass_kg),
sd_body_mass_kg = sd(body_mass_kg)
)
OUTPUT
`summarise()` has grouped output by 'year', 'island'. You can override using
the `.groups` argument.R
head(bm_byyear_byisland_byspecies)
OUTPUT
# A tibble: 6 × 5
# Groups: year, island [4]
year island species mean_body_mass_kg sd_body_mass_kg
<chr> <chr> <chr> <dbl> <dbl>
1 2007 Biscoe Adelie 3.62 0.292
2 2007 Biscoe Gentoo 5.07 0.583
3 2007 Dream Adelie 3.67 0.527
4 2007 Dream Chinstrap 3.69 0.328
5 2007 Torgersen Adelie 3.79 0.441
6 2008 Biscoe Adelie 3.63 0.478
Connect mutate with logical filtering: ifelse
When creating new variables, we can hook this with a logical
condition. A simple combination of mutate() and
ifelse() facilitates filtering right where it is needed: in
the moment of creating something new. This easy-to-read statement is a
fast and powerful way of discarding certain data (even though the
overall dimension of the data frame will not change) or for updating
values depending on this given condition.
R
## keeping all data but "filtering" after a certain condition
# calculate bill length / depth ratio for only for Adelie penguins
bill_morph_adelie <- penguins |>
mutate(
bill_ratio = ifelse(
species == "Adelie",
bill_length_mm/bill_depth_mm,
NA
)
)
head(bill_morph_adelie)
OUTPUT
# A tibble: 6 × 9
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen 43.9 17.2 201. 4202.
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
# ℹ 3 more variables: sex <chr>, year <chr>, bill_ratio <dbl>Challenge 1
Write a single command (which can span multiple lines and includes pipes) that will produce a data frame with the penguins found on Torgersen island, including the columns species, body_mass_g, and year, but not for other islands. How many rows does your data frame have, and why?
You should start from the penguins tibble.
R
penguins_torgersen <- penguins |>
filter(island == "Torgersen") |>
select(species, body_mass_g, year)
head(penguins_torgersen)
OUTPUT
# A tibble: 6 × 3
species body_mass_g year
<chr> <dbl> <chr>
1 Adelie 3750 2007
2 Adelie 3800 2007
3 Adelie 3250 2007
4 Adelie 4202. 2007
5 Adelie 3450 2007
6 Adelie 3650 2007 Using head(penguins_torgersen) tells us that our output
is “A tibble 52 x 3” i.e. a tibble with 52 rows and 3 columns.
Alternative solutions to find the shape of the tibble:
R
dim(penguins_torgersen)
OUTPUT
[1] 52 3R
nrow(penguins_torgersen)
OUTPUT
[1] 52R
ncol(penguins_torgersen)
OUTPUT
[1] 3Challenge 2
Calculate the average flipper length per species. Which species has the longest average flipper length, and which has the shortest?
You should start from the penguins tibble.
R
body_mass_by_species <- penguins |>
group_by(species) |>
summarize(mean_body_mass = mean(body_mass_g))
body_mass_by_species |>
filter(mean_body_mass == min(mean_body_mass) | mean_body_mass == max(mean_body_mass))
OUTPUT
# A tibble: 2 × 2
species mean_body_mass
<chr> <dbl>
1 Adelie 3704.
2 Gentoo 5069.Another way to do this is to use the dplyr function
arrange(), which arranges the rows in a data frame
according to the order of one or more variables from the data frame. It
has similar syntax to other functions from the dplyr
package. You can use desc() inside arrange()
to sort in descending order.
R
body_mass_by_species |>
arrange(mean_body_mass) |>
head(1)
OUTPUT
# A tibble: 1 × 2
species mean_body_mass
<chr> <dbl>
1 Adelie 3704.R
body_mass_by_species |>
arrange(desc(mean_body_mass)) |>
head(1)
OUTPUT
# A tibble: 1 × 2
species mean_body_mass
<chr> <dbl>
1 Gentoo 5069.Alphabetical order works too
R
body_mass_by_species |>
arrange(desc(species)) |>
head(1)
OUTPUT
# A tibble: 1 × 2
species mean_body_mass
<chr> <dbl>
1 Gentoo 5069.Advanced Challenge
Calculate the average body mass in 2007 of 10 randomly selected
penguins for each species. Then arrange the species names in reverse
alphabetical order. Hint: Use the dplyr
functions arrange() and sample_n(), they have
similar syntax to other dplyr functions.
R
body_mass_10penguins_byspecies <- penguins |>
filter(year == "2007") |>
group_by(species) |>
sample_n(10) |>
summarize(mean_body_mass = mean(body_mass_g)) |>
arrange(desc(species))
body_mass_10penguins_byspecies
OUTPUT
# A tibble: 3 × 2
species mean_body_mass
<chr> <dbl>
1 Gentoo 5405
2 Chinstrap 3648.
3 Adelie 3500.Further reading
We recommend the following resources for some additional reading on the topic of this episode:
R for Data Science (online book)
Data Wrangling Cheat sheet (pdf file)
Introduction to dplyr (online documentation)
Data wrangling with R and RStudio (online video)
Tidyverse Skills for Data Science (online book)
Key Points
- Use the
dplyrpackage to manipulate data frames. - Use
select()to choose variables from a data frame. - Use
filter()to choose data based on values. - Use
group_by()andsummarize()to work with subsets of data. - Use
mutate()to create new variables.